
#后门攻击 #不可见后门
Article
Nguyen, Anh, 和Anh Tran. 《WaNet -- Imperceptible Warping-based Backdoor Attack》. arXiv, 2021年3月3日. https://doi.org/10.48550/arXiv.2102.10369.
Data
背景:
目的:
现有的触发器建立在噪声扰动基础上,隐蔽性不足,为增强触发器的隐蔽性。
结论:
- Wanet可以成功攻击且绕过SOTA防御方法
- Wanet可以躲过网络检查和人眼感知
方法:
- 提出一种基于扭曲的触发器
- 提出一种创新的训练模型方法——“噪音”模式
构造扭曲触发器
整体流程:
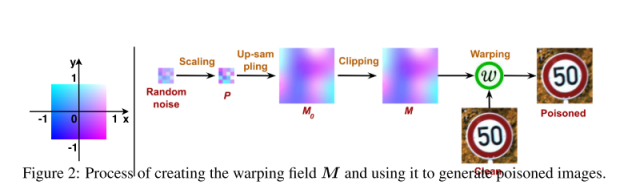
B(x)为后门注入函数,W是扭曲函数,M是一个预定义的变形空间(运动场),它为目标图像中的每个点定义了向后扭曲的相对采样位置。
M的三个要求:
- 足够小
- 弹性、平滑
- 在图像边界之内
噪音模式
作用:避免模型仅学习到像素级伪像
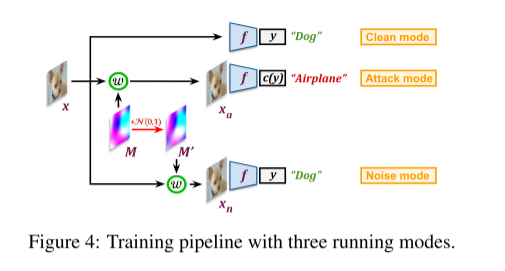
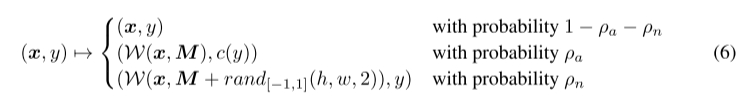
设置两个超参数\rho_{\alpha}和\rho_{n},依概率输入三种数据:
- 干净数据
- 后门数据
- 带高斯噪声扰动的后门数据,但输出正常标签
结果:
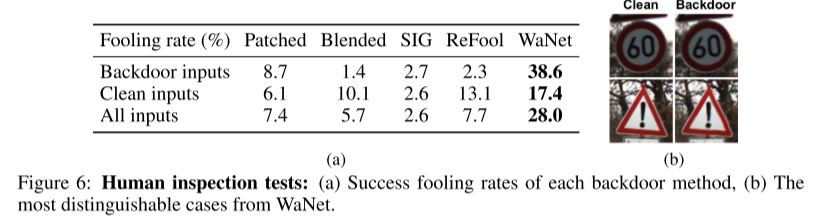
人眼感知实验
选择25张后门图和25张干净图让测试员判断,得到误分类的概率,可见前四种情况,测试员基本可以很好的判断。而WaNet误分类的概率是其他算法的四倍之多。
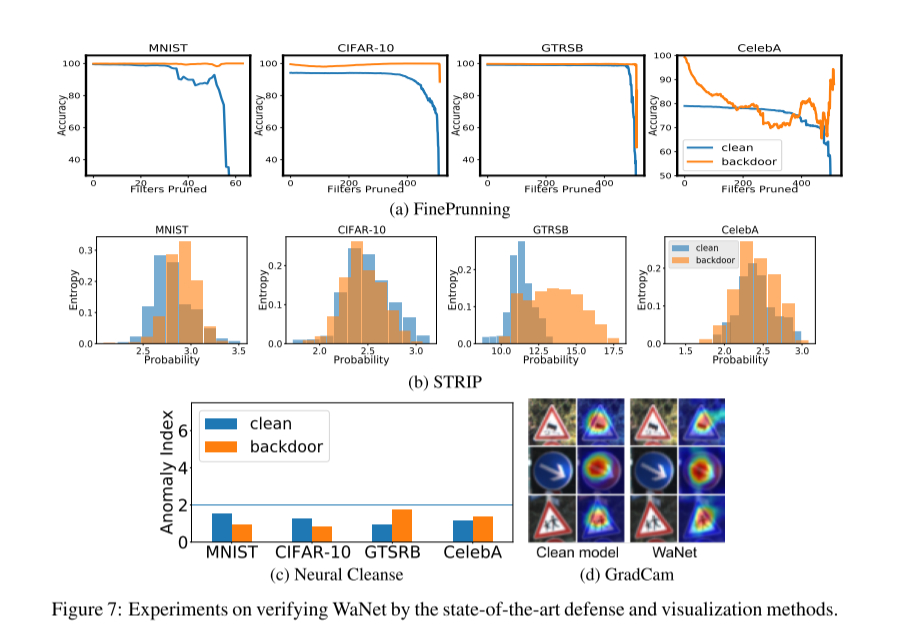
应对后门防御实验
FP算法:基本上不奏效,当攻击成功率下降时,模型精度也会下降。
消融实验
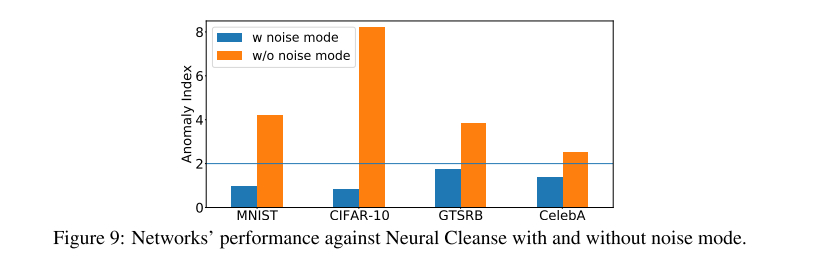
可见没有用”噪音“模式训练的模型(黄色),异常值更高
Comment
“噪音”模式像是对抗训练的思路
人眼对于微弱的颜色变化应该也不太敏感,是否可以对图片做颜色的变化,
现实世界的鲁棒性也需要考虑,用相机拍屏幕上的照片的话,很可能颜色会被微小。
创新思路推演:”噪音“模式的提出是由于WaNet原始版本在神经清理防御下被清理了大半,效果很明显。
Why
Summary
不可见后门攻击
Notes
intro:
人类不擅长识别细微的图像扭曲,如微小的几何变换,但机器十分擅长这项任务
图片隐蔽性强的话,当作开源数据集,不会有人察觉,因此会造成很大的安全风险
pixel-wise artifacts:像素级伪像,图像进行微小的、不可察觉的扰动,使得神经网络对图像的分类结果发生错误。作者用噪音模式来强化模型去学习图片弯曲的特性本身,而不是像素级伪像。
如下图,图2是没有用”噪音“模式的后门攻击,经过神经清理算法后,只剩下了一些伪影,而图3经过”噪音“模式训练,学习到了扭曲的特征,而不是一种微小的扰动。

目前两种训练集中毒的模式:
- 改变数据,也改变标签
- 只改变数据,不改变标签(Clean Label)
能够躲过SOTA防御的原因:以前的后门攻击都是用图像补丁,而该方法是基于图像变形。(那图片风格肯定呢?两者都不是,图片风格和加随机扰动有啥区别呢,特征更明显?)