
Article
Salem, Ahmed, Rui Wen, Michael Backes, Shiqing Ma和Yang Zhang. 《Dynamic Backdoor Attacks Against Machine Learning Models》. 收入 2022 IEEE (EuroS&P), 703–18, 2022. https://doi.org/10.1109/EuroSP53844.2022.00049.
arxiv:2020年
Data
背景:
previous work is based on static patterns and locations
目的:
- 提出一种动态触发器算法
- 提出一种针对动态触发器的防御方法
结论:
在MNIST, CelebA, and CIFAR-10三个数据集中表现好,且SOTA防御算法(ABS,Februus, MNTD, Neural Cleanse, and STRIP)无法大幅度的降低动态后门的ASR。
方法:
1:动态后门技术
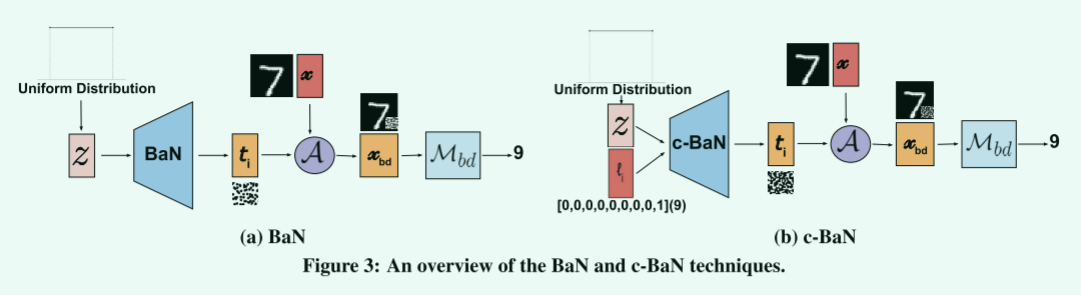
包括随机后门RB、后门生成器网络BaN、条件后门生成器网络c-BaN
1.1 RB
在均匀分布中随机采样生成触发器,嵌入输入数据的随机位置。
数学模型定义:A(x,ti,ki) = x_{bd}
- x是输入向量
- ti是触发器
- ki是嵌入位置信息
- x_{bd}是带有后门的输入向量
令T是给定的触发器集合,K是给定位置集合,ti∈T,ki∈K,从两个集合中随机取。
分布也可以用高斯分布等其他类型,来改变触发器外观。
多标签后门场景:将K分成若干个不相交的子集K_{i},分别对应于目标标签l_{i}
1.2 BaN
BaN源于GAN网络的启发,不同之处在于BaN将GAN的鉴别器换成了目标模型M,且BaN和M不是对抗训练关系,而是联合优化学习最佳的生成触发器和模型学习到触发器的方式。
单目标标签攻击的训练步骤:
- 从均匀分布中选出噪声向量输入到后门生成模型BaN,生成触发器t
- 用干净数据输入到目标模型M,得到交叉熵损失\gamma_{c}
- 将触发器t注入干净数据,输入到模型M,计算输出和目标标签的后门损失\gamma_{backdoor}
- 目标模型基于联合损失\gamma_{c}+\gamma_{backdoor}更新,BaN用\gamma_{backdoor}改进生成的触发器
多目标标签攻击:后门损失改成多个后门损失之和\sum_{i}\gamma_{backdoor_{i}},其中i对应不同的目标标签
1.3 c-BaN
RB和BaN都要求一个位置只允许嵌入一种触发器,在多个目标标签下,具有不相交的位置集合的限制。因此c-BaN基于BaN改进了输入结构,使得每个目标标签不需要具有其唯一的触发位置
相比于BaN的两点区别:
- 在多目标场景下,不需要给每个目标标签划分不相交的位置集合K_{i}
- c-BaN在输入端加上了一个独热编码处理过的目标标签向量
该框架的应对后门防御的方法:将任何防御作为鉴别器添加到BaN/c-BaN中,通过设定惩罚损失使得触发器尽可能的绕过模型的防御
2. 动态触发器防御算法
采用去噪算法:比如用自编码器,用干净数据来训练AE,再重建训练集。实验结果表明在简单数据如MNIST上重建效果好,能够较好抵御后门攻击,但在如CIFAR这样有多通道的相对复杂图片来说,重建效果不好,目标模型的准确性对于干净和后门数据集分别下降了4.8%和25%
作者提出另外一种想法:首先计算重建输入和原始输入之间的距离,然后基于预定阈值决定是否将输入转发到模型。(阈值不好定)
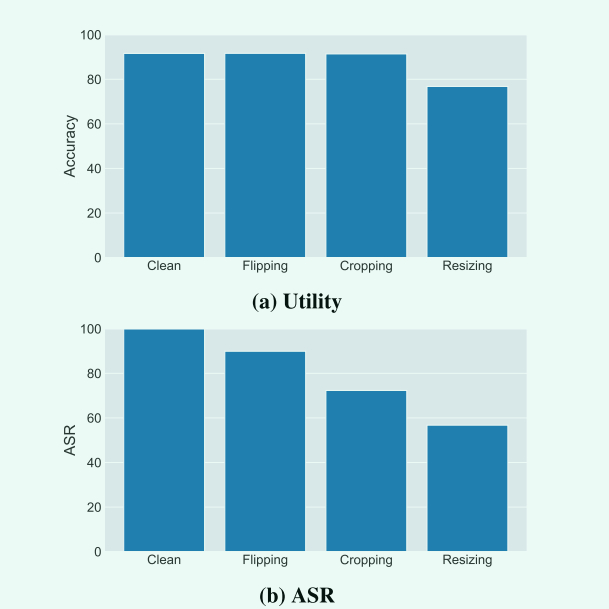
数据增强:将图片翻转、放缩、裁剪,以此让后门失效。
- 翻转结果只将ASR下降到88.6%(单目标标签RB)和93.4%(全标签c-BaN),说明BaN算法对翻转有弹性效果
- 放缩:图片大小从16 * 16变成32 * 32,结果ASR下降40%的同时模型精确度下降15%以上
- 裁剪:32 * 32的图片,填充边界像素到40 * 40,填充值用0(黑色),然后在(0,0)~(8,8)之间随机选择一个的位置,剪裁回原始大小。结果:ASR下降到73.2%和89.2%,模型精确度下降了0.7%和 0.25%。
由以上实验得出:数据增强可以降低后门攻击的准确度,但不能防止它。
结果:
实验模型
BaN的网络模型: ReLU在全连接层间作为激活函数,|t|是触发器的大小
ReLU在全连接层间作为激活函数,|t|是触发器的大小
c-BaN:最开始由两个完全独立的全连接层组成,分别输入噪音向量和独热编码的目标标签向量,然后在下一层之前将两层的输出连接在一起。

实验评估
1 性能表现
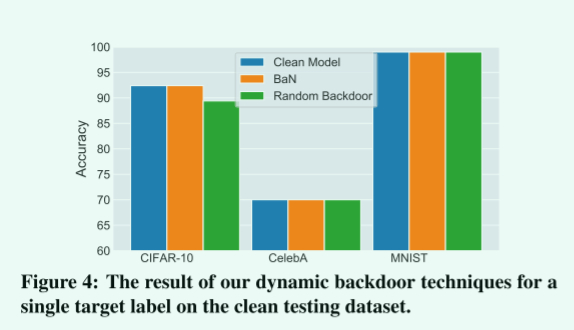
单目标下:
ASR都是100%,CSR除了在CIFAR下有2%性能下降,另外两个性能不变
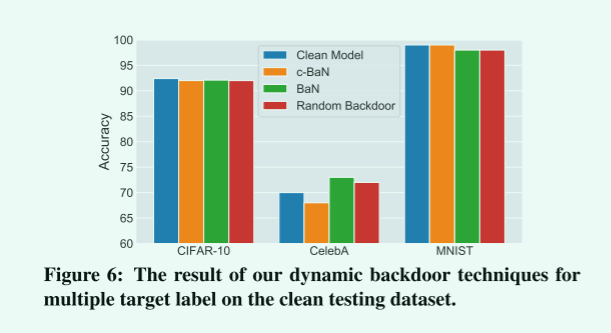
多目标下:
ASR都是接近100%,主要看CSR,性能差距都在2%不到,注意到的是CelebA数据集下,BaN和RB比干净模型的精确度还高,作者考虑是随机后门有正则化效果。
注意力可视化实验:可以看到注意力从动物的脸部转移到了后门触发器上。

2 对抗防御检测的性能
2020年之前的SOTA基于模型的防御算法:Neural Cleanse,ABS , and MNTD
原理:在模型检测是否包含后门。
结果是不能有效的检测出所有后门。
原因:
- 这些防御算法基于的假设是触发器的位置和特征是一致的
- 实验中为所有可以设置触发器的标签都嵌入了触发器,使得检测更加困难
MNTD是一种神经分析分类器,通过创建内存节点并记录内存节点状态,MNTD可以检测神经网络执行过程中的异常行为,并清除神经网络后门。最初MNTD以95%以上的精确度检测出模型存在后门,但作者在训练中额外加入一个元分类器(与用于评估的数据集相比,具有不相交的数据集)作为鉴别器,将精确度下降到2%左右
2020年之前的SOTA基于数据集的防御算法:STRIP,Februus
原理:尝试对训练集进行检测是否含有后门。
Februus只能将ASR从100%降到70-80%,而对于静态触发器,该防御可以将ASR降到0.25%,证明了动态触发器在应对目前后门防御检测的优势。
威胁模型
- 如果要将BaN和目标模型联合优化,攻击者必须控制模型的训练过程和训练集(外包给其他人做)
- 如果放宽威胁模型,攻击者只能控制训练集,那么攻击者可以使用预训练的BaN(触发器的可转移性),实验测试了在CIFAR下预训练的BaN在MNIST数据集下ASR仍是100%,联合优化的优势在于可以往目标模型中使用定制的损失函数。另一方面,没有联合优化,中毒数据需要在10%以上才能有效果。
Comment
1:隐藏性不太够
- 一种想法是:动态生成的后门图案希望和图片较为相似,满足隐蔽性条件,但又能够被网络学习。
- 另一种是采用《A new Backdoor Attack in CNNs by training set corruption without label poisoning》这篇论文类似的斜坡函数或者正弦信号,叠加到训练集中,位置选择算法可以保持不变。
2:对于带有生物图像比如人、动物的数据集,通过注意力可视化方法可以看到,重点都在面部,那么是否可以选择将后门重点放在面部区域,这样更加容易被学习呢?
先通过其他模型找到训练数据集的不同目标类的注意力点,然后插入后门
Why
Summary
第一个通过生成器网络生成触发器的算法
提出三种效果递进的动态生成触发器算法,不仅有几乎完美的攻击成功率,而且能很好的绕过2020年SOTA后门防御机制。